

This activity is awesome because you can do it with any kid who can color…your 4-year-old or your 14-year-old. Heck, a 44-year-old will love this activity, too. At it’s basic level, your child will need to use some logical thinking to complete the activity. At a deeper level, this activity introduces the Four Color Theorem, and this might be an intriguing topic for you and your older child. But first, let’s color.
Grab a piece of paper and draw this:

Hand your kid two different colored crayons or markers or whatever. Maybe even let the kid choose his two favorite colors. Then say that the only rule is two squares that share the same border cannot be the same color. Then watch.
Your child might understand right away and quickly color in a checkerboard.
My 8-year-old did not. He looked at the paper for a long time. Then he looked at me. I wondered what was so darned difficult. Then he asked, “Do corners count as touching?”
Oh. Valid question. And evidence again that he is actively thinking when I am wondering why the heck he is just staring.
“No. Corners do not count as a shared border.”
With that clarified, he began to color.

It’s good to start with that fairly trivial example of coloring a checkerboard pattern with two colors. First, it will help iron out any wrinkles in the instructions (as happened with my son.) Second, it is very accessible. Anyone can give it a try without too much angst.
Now draw these:

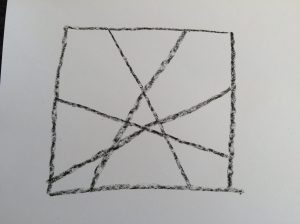
The directions are the same, but this time 3 colors are allowed. (You might ask your child to try it first as a two-color pattern. Whether you do or not depends on how your child responds to a little frustration and how far you want to take this activity. I handed my son three colors, because I wanted to move more swiftly to the 4-color problem. When I did this activity with a 14-year-old, I did not tell him how many colors he would need.)

Finally, try this one:
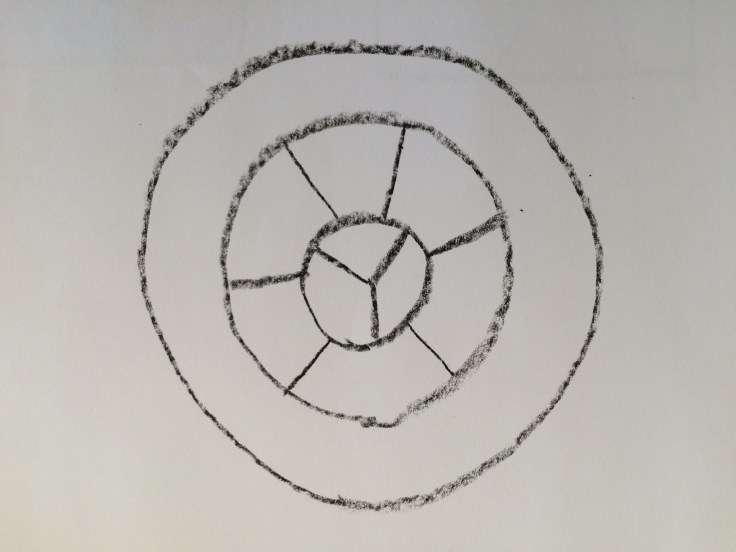
Again, you can let your child try to figure out whether 2 or 3 or more colors are needed. Or you can tell him (it’s 4.) This is a challenging one. Obviously it would be easier with 5 or 6 or more colors. But the point is that you only need 4 to satisfy the rule. The 8-year-old and I worked on it together, and we only tried once (and failed) before he decided it was time to play LEGO. The 14-year-old had more interest and stamina for it. He has been thinking about it for over a week (not continuously, though, let’s assume!) At one point he tried to explain to me why it was impossible with 4 colors. It is possible. I left him to continue thinking about it on his own, because he still seemed quite engaged with the problem. If he hadn’t been, I would have given him a nudge to bait his interest again. (And, to be honest, at that point I hadn’t yet figured out a way to color the pattern.)
Don’t be too upset with me. I’m not going to include a picture of the 4-color solution. It’s good to fiddle with a problem for a while!
(Mathematically…the act of stepping through the logical possibilities while trying to color these patterns will help develop critical thinking skills. This activity is based on the Four Color Theorem, which states that any map can be colored with just 4 colors following the rule that no two spaces sharing a border may be the same color. A more official statement of theorem is given any separation of a plane into contiguous regions, producing a figure called a map, no more than four colors are required to color the regions of the map so that no two adjacent regions have the same color. Whew. Theorems in math must be proved, and this one’s proof was elusive for a long time. The theorem was first stated in 1852, but it wasn’t proved until 1976. Efforts to find a proof led to the development of Graph Theory. Did you learn that in school? I didn’t. But I’m pretty sure I would have enjoyed coloring as a gateway into deeper mathematical topics. I only first heard of the Four Color Theorem and this activity from another mathy mom. Her blog, Musings of a Mathematical Mom, is another source of inspiration, and I highly recommend it.)

Love to engage a kid with something other than a laptop 🙂
LikeLike
I love this puzzle map project! So fun to learn about this theorem, too.
LikeLike
This is a fabulous blog that I really enjoy. I consider myself a math person although I see my grandsons and granddaughters doing math in elementary school that was only for the top students overall. 5 stars.
LikeLike